#Avocado Data
캐글의 유명한 데이터셋. 한때 젊은 층 사이에서 열풍을 불렀던 주인공 아보카도의 가격을 예측하는 것을 목적으로 배포되는 데이터셋이다.
캐글 홈페이지에 들어가서, avocado 를 검색하면 최상단에 위치해 있고, 무료로 다운받을 수 있다.

필자는 다운받은 Avocado 데이터를 구글 드라이브에 올려놓고, 캐글에서 이용하기 위해 드라이브 마운트를 하여 Pandas 라이브러리를 이용해 데이터를 불러오는 작업을 거쳤다. 이제 막 머신러닝 공부를 시작했다면 복잡하지 않으면서 쉬운 방법이라고 생각한다.
#Make Model
기본적으로 Keras를 이용해서 간단한 신경망을 구현하였고, 데이터의 전처리는 Scikit-Learn을 이용하였다.

모델을 구축하기 위해 필요한 라이브러리들을 import 해 놓고, 필자는 원래 tensorflow 2.x 버전이 코랩에 설치되어 있지만 기존의 keras를 사용하기 위해서 텐서플로우 다운그레이드 매직을 실행햐였다.

Pandas의 read_csv() 함수를 사용해 아보카도 데이터를 읽어왔다. 이때 아보카도 데이터타입은 pandas dataframe 이 된다.

다운받은 데이터셋의 크기도 한번 확인해 주고, describe() 메서드를 사용하면 해당 데이터의 수치 정보(평균, 표준편차, 최솟값 최댓값 등)을 확인할 수 있다.
이번 Avocado Price 예측 모델 만들기 1탄에서는, 다른 정보들은 사용하지 않고, 오로지 판매량/과일 크기 데이터만을 이용해서 가격을 예측해 볼 것이다.

여기서 avocado_volume 은 total volume 데이터이고, avocado_typenum 은 아보카도 Type 데이터에서 Type이 conventional 이면 1, organic 이면 2 값을 준 데이터이다.
분포도를 보면 무언가 규칙성이 있어 보이는데 그렇다고 크게 상관관계가 있는 것 같지도 않다. 사실 이는 다른 영향을 미치는 변수들을 제외하고 오로지 Total Volume 만 고려한 것이기 때문에, 전형적인 다차원 데이터 분포도를 2차원으로 투영했을 때 나타나는 모양에 해당한다.
아래 막대 그래프를 보면, type 1 일 경우보다 type 2 에서 가격 범위가 더 큰 것을 볼 수 있다. 여러 다른 변수들을 차치하고서라도, Type 1, 즉 Conventional 타입의 avocado 는 가격의 상한선이 존재한다는 것이다.
우선 1탄에서는 실제 간단한 신경망 모델 구현의 흐름을 알아보기 위한 것이기 때문에 이대로 학습을 시켜보도록 하자.
그 전에 먼저 데이터 전처리를 해야 한다. 신경망은 input 데이터들의 스케일이 동일해야 학습을 잘 할 수 있기 때문에, scikit-learn의 MinMaxScaler() 함수를 이용하여 데이터 정규화를 시켜주도록 한다.
* input 특성 데이터의 스케일이 상이하면 신경망 모델은 큰 스케일의 특성 데이터에 영향을 많이 받고, 이는 학습을 불안정하게 만든다.

수치 데이터를 정규화 시켜 주고, 전체 데이터셋을 20퍼센트 비율로 train 셋과 test 셋으로 나눠준 코드이다.
이제 신경망 모델을 만들어 보자.

Keras 예제에 나와 있는 모델과 비슷한 간단한 Sequential 모델을 만들고, 50번 반복해서 훈련시키도록 한다.

위 함수는 필자가 Train 데이터셋에서 훈련을 마친 신경망 모델이 Test 데이터를 가지고 얼마나 예측을 실제와 근접하게 하는지 비교하기 위해 만든 함수이다. 위 함수를 이용하면 실제 데이터 그래프와 신경망 모델이 예측한 데이터 그래프가 한 화면에 나타나게 된다.
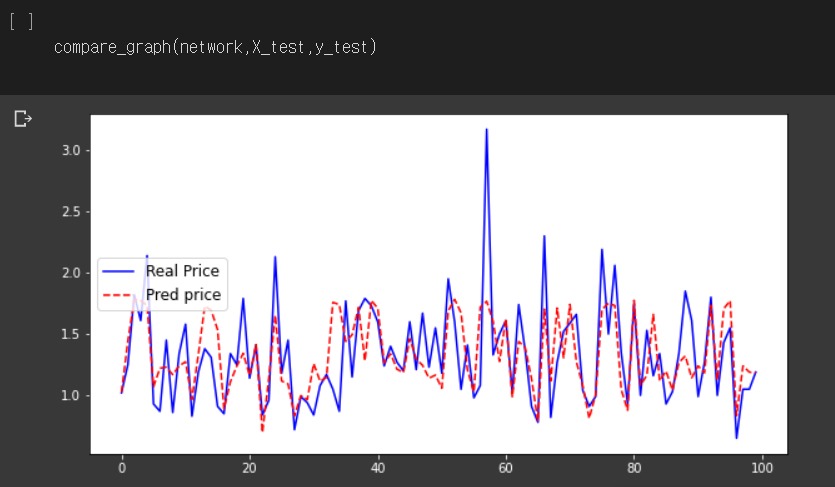
결과는 다음과 같다. 파란색 꺾은선은 실제 아보카도의 가격을, 빨간색 꺾은선은 신경망 모델이 예측한 아보카도의 가격을 나타낸다. 그냥 봤을 땐 그냥저냥 대략적인 흐름은 따라가는 것 같아 보이지만, 사실 그렇게 정확한 예측이 아니다.
그도 그럴 것이, 아보카도에 영향을 미치는 변수는 훨씬 많은데, 아주 한정적인 정보만 가지고서 학습을 했기 때문에, 잘 예측할 수 없는 것이다.
그래도 실제 데이터를 바탕으로 신경망 모델을 훈련시키는 대략적인 과정에 대해서 간단히 알아보았다.
2탄에서는, 보다 정확한 예측을 위해서, 시각적 분석을 포함해 모든 데이터를 기반으로 여러 가지 종류의 전처리 과정을 거친 후, 학습시키는 과정에 대해서 설명하도록 하겠다.
'Artificial Intelligence > Machine Learning' 카테고리의 다른 글
| [Colab / Keras] Avocado Price 예측 모델 만들기 2 (0) | 2020.04.24 |
|---|---|
| [Keras Deep Learning] 신경망 Tutorial (0) | 2020.04.18 |
| 핸즈온 머신러닝(8) - 앙상블 학습 (2) | 2020.01.29 |
| 핸즈온 머신러닝(7) - 결정 트리 (1) | 2020.01.28 |
| 핸즈온 머신러닝(6) - 서포트 벡터 머신 2 (0) | 2020.01.27 |




댓글